💾 Database Transactions and Concurrency
Complete Guide for Database Management Systems
💡 What is a Transaction?
A transaction is a collection of operations that performs a single logical unit of work in a database application.
🔍 Real-World Example: Banking Transfer
Imagine you're using a banking app to transfer ₹1000 from Account A to Account B.
This task involves multiple operations:
1. BEGIN TRANSACTION
2. Deduct ₹1000 from Account A
3. Add ₹1000 to Account B
4. COMMIT TRANSACTION
This entire process is one transaction. If any step fails, the whole operation must be rolled back.
🧱 Operations in a Transaction
In a transaction, an operation is a single database action like reading, writing, updating, or committing data.
Multiple operations together complete the logical task of the transaction.
✅ Common Database Operations
- BEGIN TRANSACTION – Initialize the transaction
- READ(X) – Read the value of variable X
- WRITE(X) – Update the value of variable X
- COMMIT – Make changes permanent
- ROLLBACK/ABORT – Cancel transaction and undo changes
📘 Detailed Example: Transfer ₹1000 from A to B
Transaction T1:
1. BEGIN TRANSACTION
2. READ(A) -- Get current balance of Account A
3. A = A - 1000 -- Calculate new balance (deduct ₹1000)
4. WRITE(A) -- Update Account A with new balance
5. READ(B) -- Get current balance of Account B
6. B = B + 1000 -- Calculate new balance (add ₹1000)
7. WRITE(B) -- Update Account B with new balance
8. COMMIT -- Make all changes permanent
✅ ACID Properties (Critical for Interviews)
ACID properties are fundamental principles that ensure database transactions are processed reliably and maintain data integrity, even during system failures or concurrent access.
🔄 Atomicity
All operations in a transaction are treated as a single, indivisible unit – either all operations succeed completely or none are applied at all.
💡 Real-World Example:
During a ₹1000 transfer from Account A to B, if the deduction from Account A succeeds but adding to Account B fails, the system must automatically rollback the deduction to maintain consistency.
BEGIN TRANSACTION
Deduct ₹1000 from A → SUCCESS
Add ₹1000 to B → FAILURE
ROLLBACK -- Automatically undo deduction from A
⚖️ Consistency
The database must remain in a valid state before and after the transaction, maintaining all defined rules, constraints, and relationships.
💡 Real-World Example:
The total money in the banking system must remain constant during transfers. Also, business rules like "account balance cannot be negative" must be enforced.
Before Transaction:
A = ₹5000, B = ₹3000 → Total = ₹8000
After Transaction (₹1000 A to B):
A = ₹4000, B = ₹4000 → Total = ₹8000 ✅
Constraint Check: Both balances ≥ 0 ✅
🔒 Isolation
Each transaction executes independently without interference from concurrent transactions. Intermediate results of one transaction are not visible to others until completion.
💡 Real-World Example:
Two users making simultaneous transfers from the same account should not see each other's intermediate balance calculations, preventing incorrect final balances.
User 1: Transfer ₹500 A → B (concurrent)
User 2: Transfer ₹300 A → C (concurrent)
-- Isolation ensures both transactions see the original
-- balance of A and calculate correctly without interference
💾 Durability
Once a transaction is committed successfully, the changes are permanently stored and will survive system crashes, power failures, or other system problems.
💡 Real-World Example:
After a successful online payment shows "Transaction Complete", even if the system crashes immediately afterward, the payment record is permanently saved and cannot be lost.
COMMIT TRANSACTION → SUCCESS
-- Data written to persistent storage (disk/logs)
-- After power failure: data recovered from logs ✅
-- Transaction effects are permanent
🤝 Concurrent Execution
When multiple transactions execute simultaneously on the same database, it's called concurrent execution. This is essential for modern database performance.
🎬 Movie Ticket Booking Example
Consider a popular movie release where thousands of users are booking tickets simultaneously. The system must process many concurrent transactions while ensuring that:
Transaction 1: User A books Seat 5A at 2:15 PM Transaction 2: User B books Seat 7C at 2:15 PM Transaction 3: User C attempts Seat 5A at 2:15 PM ← Must be prevented! Result: Only User A gets Seat 5A, User C sees "Seat Unavailable"
🔄 Transaction States
Every transaction in a DBMS goes through a well-defined sequence of states to ensure safe execution and proper recovery capabilities.
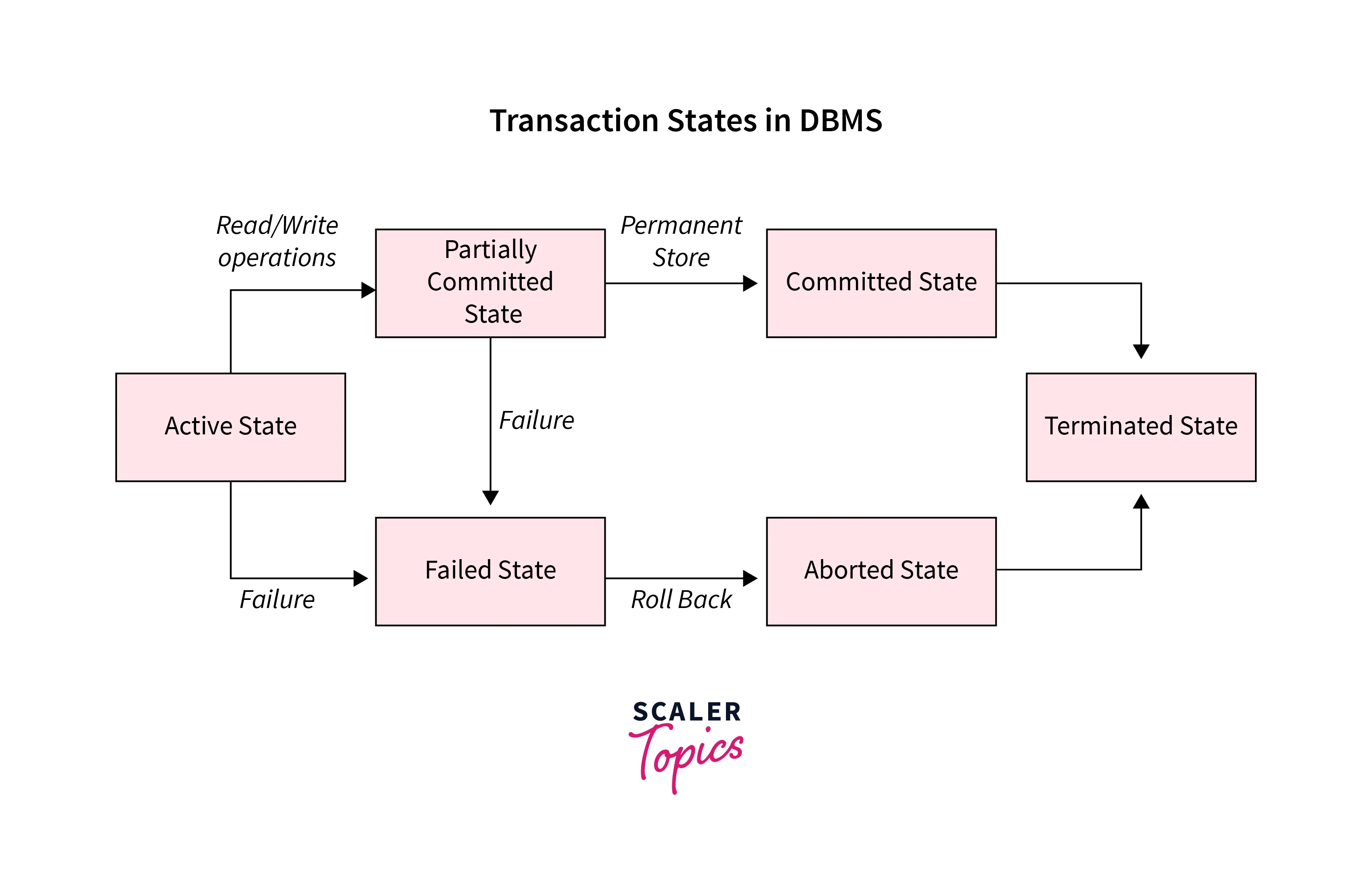
Transaction State Diagram showing the lifecycle from Active to Terminated
🧭 Detailed Explanation of Transaction States
| State | Description | Next State | Real-World Example |
|---|---|---|---|
| Active | Transaction is currently executing read/write operations | → Partially Committed (success) → Failed (error occurs) |
User clicks "Transfer ₹500" and operations are being processed |
| Partially Committed | All operations completed successfully, but changes not yet made permanent | → Committed (if write to disk succeeds) → Failed (if write fails) |
Transfer calculations complete, waiting for database write confirmation |
| Committed | All changes successfully written to permanent storage | → Terminated | User sees "Transfer Successful" message, money actually moved |
| Failed | Error occurred during execution, transaction cannot proceed | → Aborted | Network timeout during transfer or insufficient balance detected |
| Aborted | Transaction rolled back, all changes undone | → Terminated | Failed transfer rolled back, original balances restored |
| Terminated | Transaction completed (either successfully committed or aborted) | End state | System ready for new transactions, resources freed |
📘 Complete Transaction Lifecycle Example
Mobile Recharge Transaction:
1. ACTIVE: BEGIN TRANSACTION
2. ACTIVE: READ(wallet_balance) → ₹1000
3. ACTIVE: wallet_balance = wallet_balance - ₹100 → ₹900
4. ACTIVE: WRITE(wallet_balance)
5. ACTIVE: Send recharge request to telecom provider
6. PARTIALLY COMMITTED: All operations executed successfully
If telecom confirms recharge:
7. COMMITTED: Changes written to disk
8. TERMINATED: Show "Recharge Successful"
If telecom rejects recharge:
7. FAILED: Recharge request denied
8. ABORTED: Rollback wallet_balance to ₹1000
9. TERMINATED: Show "Recharge Failed"
📅 What is a Schedule?
A Schedule is the chronological order in which operations from multiple concurrent transactions are executed by the database system.
📊 Types of Schedules:
🔄 Serial Schedule
T1: READ(A) → WRITE(A) → COMMIT T2: READ(B) → WRITE(B) → COMMIT
Transactions execute one after another (no overlap)
Advantage: Always consistent and safe
Disadvantage: Poor performance due to no parallelism
🔀 Concurrent Schedule
T1: READ(A) T2: READ(B) T1: WRITE(A) T2: WRITE(B) T1: COMMIT T2: COMMIT
Operations from different transactions are interleaved
Advantage: Better performance and resource utilization
Risk: May cause data inconsistency if not properly controlled
⚠️ Concurrency Control Problems
When multiple transactions execute concurrently without proper control mechanisms, several serious problems can occur that compromise data integrity and consistency.
💥 1. Dirty Read (Reading Uncommitted Data)
Problem Definition
A transaction T2 reads data that has been modified by transaction T1, but T1 has not yet committed. If T1 later aborts, T2 has used incorrect data for its operations.
🛍️ Real-World Example: Online Shopping
Your friend T1 adds ₹500 worth of items to their cart (reducing available inventory), and you T2 check the stock showing "2 items left". However, T1's payment fails and the transaction rolls back. You made your purchase decision based on incorrect stock information.
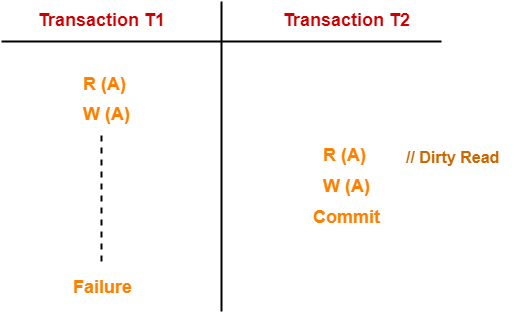
Timeline showing how T2 reads uncommitted changes from T1
🧠 Step-by-Step Analysis:
- t1–t3 (T1): T1 reads account A, deducts ₹500, writes new balance (uncommitted)
- t4–t5 (T2): T2 reads A's modified value and uses it for calculation
- t6 (T1): T1 encounters an error and must abort
- t7 (T1): T1 rolls back, undoing its changes
- t8 (T2): T2 commits based on the incorrect data it read
📝 2. Lost Update Problem
Problem Definition
Two transactions read the same data item, modify it independently, and both update the database. The update from one transaction overwrites the update from the other, resulting in lost changes.
🛍️ Real-World Example: Inventory Management
Alice and Bob are both warehouse managers updating the same product's quantity. Alice reduces it by 1 (sold), Bob increases it by 3 (restocked). Due to poor timing, Bob's update overwrites Alice's, making it appear the sale never happened.

Timeline showing how Bob's update overwrites Alice's changes
🧠 Step-by-Step Analysis:
- Step 1: Alice reads quantity = 7 (original value)
- Step 2: Bob reads quantity = 7 (same original value)
- Step 3: Alice calculates 7-1=6 and commits her update
- Step 4: Bob calculates 7+3=10 (based on original value) and commits
- Final Result: Database shows quantity = 10, but should be 9 (7-1+3)
🔄 3. Non-Repeatable Read
Problem Definition
A transaction reads the same data item multiple times and gets different values because another transaction modified and committed the data between the reads.
🛍️ Real-World Example: Price Comparison
You're comparing product prices: first read shows ₹1000, you check other products, then read the same product again and see ₹1200. Another user's price update transaction occurred between your two reads.
T1 (Your Session):
READ(product_price) → ₹1000
... (checking other products)
T2 (Admin Session):
UPDATE product_price = ₹1200
COMMIT
T1 continues:
READ(product_price) → ₹1200 (different value!)
👻 4. Phantom Read
Problem Definition
A transaction executes a query (with WHERE condition) multiple times and gets different result sets because another transaction inserted or deleted rows that match the condition.
🛍️ Real-World Example: Report Generation
You're generating a sales report for products priced above ₹500. First query returns 10 products. While processing, new products are added. Second query returns 15 products, creating inconsistent report data.
T1 (Report Generation):
SELECT COUNT(*) FROM products WHERE price > 500; → 10 rows
T2 (Product Addition):
INSERT INTO products VALUES ('New Product', 600);
COMMIT
T1 continues:
SELECT * FROM products WHERE price > 500; → 11 rows (phantom!)
🔄 Schedule Recoverability
When multiple transactions interact with shared data, the system must ensure that it can recover properly from failures. This leads us to classify schedules based on their recoverability properties.
✅ Recoverable Schedule
Definition
A schedule is recoverable if, for every pair of transactions T1 and T2, if T2 reads data written by T1, then T1 must commit before T2 commits.
🛍️ Real-World Example: Payroll Processing
T1 calculates and updates an employee's salary to ₹80,000. T2 reads this salary to generate tax calculations. T2 only commits its tax calculations AFTER T1 has successfully committed the salary update.
T1: WRITE(salary = ₹80,000)
T1: COMMIT ✅
T2: READ(salary) → ₹80,000
T2: Calculate taxes based on ₹80,000
T2: COMMIT ✅
❌ Non-Recoverable Schedule
Definition
A schedule is non-recoverable if a transaction T2 commits after reading uncommitted data from T1, and then T1 aborts. This makes recovery impossible.
🛍️ Real-World Example: Loan Approval
T1 updates a customer's credit score to 750. T2 reads this score and approves a loan (commits). Later, T1 encounters an error and rolls back the credit score update. The loan was approved based on invalid data!
T1: WRITE(credit_score = 750)
T2: READ(credit_score) → 750
T2: Approve loan based on score 750
T2: COMMIT ✅ (loan approved)
T1: ABORT ❌ (credit score rollback)
🔄 Cascading vs Cascadeless Schedules
✅ Cascadeless Schedule (No Cascading Rollback)
Definition: A transaction only reads data from other transactions that have already committed. This prevents cascading rollbacks.

T2 and T3 only read data after T1 commits - ensuring no cascading rollback
🧠 Timeline Analysis:
- T1: Modifies data X, then commits
- T2: Reads X only AFTER T1 commits, then commits
- T3: Reads X only AFTER T2 commits, then commits
⚠️ Cascading Schedule (Chain Rollback Risk)
Definition: When transactions read uncommitted data from other transactions, creating a chain where failure of one transaction forces rollback of multiple dependent transactions.
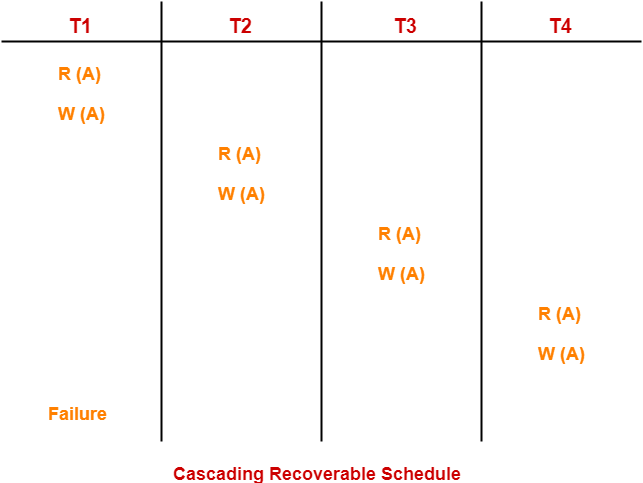
T2, T3, T4 all read uncommitted data - creating a cascade effect if T1 fails
🧠 Chain Reaction Analysis:
- T1: Modifies data X but fails before committing
- T2: Read X from T1 (uncommitted) → Must rollback
- T3: Read X from T2 (now invalid) → Must rollback
- T4: Read X from T3 (now invalid) → Must rollback
🔐 Deadlock in Database Systems
A deadlock occurs when two or more transactions are blocked indefinitely, each waiting for the other to release resources they need.
🔄 Classic Deadlock Example
Consider two users trying to transfer money between the same two accounts simultaneously:
Transaction T1 (User A): Transfer ₹100 from Account X to Account Y
1. LOCK Account X
2. Wait for LOCK on Account Y (held by T2)
Transaction T2 (User B): Transfer ₹200 from Account Y to Account X
1. LOCK Account Y
2. Wait for LOCK on Account X (held by T1)
Result: Both transactions wait forever!
🚨 Deadlock Conditions (All must be present)
- Mutual Exclusion: Resources cannot be shared simultaneously
- Hold and Wait: Transactions hold resources while waiting for others
- No Preemption: Resources cannot be forcibly taken away
- Circular Wait: A chain of transactions each waiting for the next
🛠️ Deadlock Prevention Strategies
- Resource Ordering: Always acquire locks in a predefined order (e.g., by account number)
- Timeout Mechanisms: Abort transaction if it waits too long for a resource
- Deadlock Detection: Use algorithms to detect cycles in wait-for graphs
- Timestamp Ordering: Older transactions get priority over newer ones
💡 Deadlock Prevention in Practice
// Instead of this (can cause deadlock):
Transaction T1: LOCK(Account_5), LOCK(Account_3)
Transaction T2: LOCK(Account_3), LOCK(Account_5)
// Use this (ordered locking):
Transaction T1: LOCK(Account_3), LOCK(Account_5) // Always lower ID first
Transaction T2: LOCK(Account_3), LOCK(Account_5) // Same order prevents deadlock
🧠 Real-World Applications
💳 Banking Systems
Use SERIALIZABLE isolation for money transfers to ensure absolute consistency
🛒 E-commerce
Use READ COMMITTED for product catalogs, SERIALIZABLE for checkout
📊 Analytics
Use READ UNCOMMITTED for reports where slight inconsistency is acceptable for speed
🎮 Gaming
Use REPEATABLE READ for player stats, preventing mid-game inconsistencies
🏥 Healthcare
Use SERIALIZABLE for patient records where data accuracy is life-critical
📱 Social Media
Use READ COMMITTED for feeds, allowing real-time updates without blocking
🎯 Interview Preparation Guide
🔥 Most Asked Interview Questions
- Explain ACID properties with banking examples - Focus on atomicity in money transfers
- What problems occur in concurrent execution? - Dirty read, lost update, phantom read
- How do you prevent deadlocks? - Resource ordering, timeouts, detection algorithms
- Difference between recoverable and cascadeless schedules? - Commit ordering and rollback implications
- Which isolation level would you choose for a banking app? - SERIALIZABLE with justification
- Design a solution for the lost update problem - Locking mechanisms or optimistic concurrency
- Confusing consistency (ACID) with consistency (CAP theorem)
- Thinking higher isolation levels are always better (they reduce performance)
- Not understanding that deadlock prevention and detection are different approaches
- Mixing up recoverable vs serializable schedules