What is MongoDB?
MongoDB is a NoSQL database, meaning it doesn't use tables like traditional SQL databases. Instead, it stores data in a flexible, JSON-like format called BSON (Binary JSON). It's designed to handle large amounts of data, scale easily, and work with unstructured or semi-structured data.
Document-based
Stores data in documents (like JSON objects) instead of rows and columns.
Schema-less
You can store different types of data in the same collection without a fixed structure.
Scalable
Supports horizontal scaling (adding more servers) through sharding.
High Performance
Fast for read/write operations, especially with large datasets.
Flexible
Great for applications with changing data structures, like e-commerce or social media.
Key Concepts in MongoDB
Here's what you need to know about MongoDB for an interview:
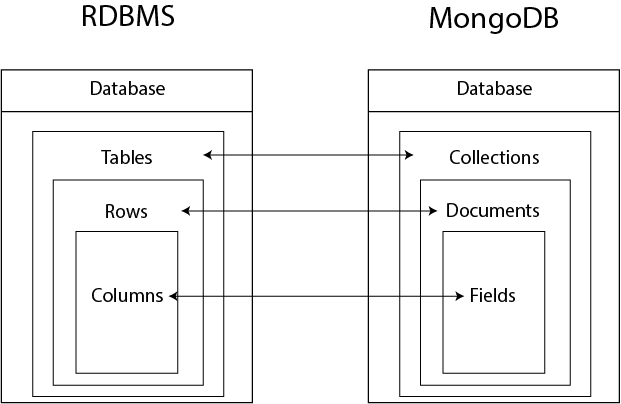
- Database: A container for collections. One MongoDB instance can have multiple databases.
- Collection: Similar to a table in SQL, but it holds documents. No fixed schema is required.
- Document: A single record in a collection, stored as a BSON object (like a JSON key-value pair).
- Field: A key-value pair in a document (e.g., "name": "John").
- _id: A unique identifier automatically added to every document (like a primary key in SQL).
- Sharding: Splitting large datasets across multiple servers to improve performance.
- Replication: Copying data to multiple servers for redundancy and high availability.
- Indexes: Used to make queries faster by allowing efficient searching on specific fields.
- Aggregation: A way to process data (like grouping, filtering, or calculating) using a pipeline.
MongoDB vs SQL
Here's a clear comparison between MongoDB (NoSQL) and SQL (Relational Databases like MySQL, PostgreSQL):
| Feature | MongoDB (NoSQL) | SQL (Relational) |
|---|---|---|
| Data Structure | Stores data in flexible, JSON-like documents | Stores data in structured tables with rows/columns |
| Schema | Schema-less (dynamic, no predefined structure) | Fixed schema (must define tables/columns upfront) |
| Scalability | Horizontal scaling (add servers, sharding) | Vertical scaling (add more power to a single server) |
| Query Language | Uses JavaScript-like queries (e.g., find()) | Uses SQL (e.g., SELECT, JOIN) |
| Joins | No native joins; data is often denormalized | Supports complex joins between tables |
| Use Case | Big data, real-time apps, unstructured data | Structured data, transactional apps |
| Performance | Fast for large-scale, unstructured data | Fast for structured data with complex queries |
| Consistency | Eventual consistency in distributed setups | Strong consistency (ACID transactions) |
When to Use MongoDB:
- When data is unstructured or semi-structured (e.g., logs, user profiles)
- For applications needing high scalability (e.g., e-commerce platforms)
- When schema changes frequently (e.g., startups building MVPs)
When to Use SQL:
- When data is highly structured and relational (e.g., financial records)
- For applications needing complex joins and transactions (e.g., banking systems)
- When strong consistency is critical
📘 MongoDB Queries with Explanations
MongoDB uses a query language that's easy to understand, especially if you know JavaScript. Here's a complete cheat sheet with explanations for interviews and practice.
🟢 1. Database Queries
Show all databases:
👉 Lists all databases available in MongoDB.
Create or switch to database:
👉 Creates (if not exists) or switches to the database mydb.
Show current database:
👉 Displays the name of the database currently in use.
🟢 2. Collection Queries
Show collections in current database:
👉 Lists all collections (like tables in SQL) inside the database.
Create collection:
👉 Creates a new collection named students.
Drop (delete) collection:
👉 Removes the students collection completely.
🟢 3. Insert Documents
Insert one document:
👉 Adds a single document (record) into students.
Insert multiple documents:
👉 Inserts multiple records in one go.
🟢 4. Find (Read) Documents
Find all documents:
👉 Retrieves all documents from the collection.
Pretty print output:
👉 Displays documents in a formatted (easy-to-read) way.
Find one document:
👉 Returns the first matching document.
Find with condition:
👉 Filters and returns only students with grade A.
Projection (only select fields):
👉 Returns only name and grade fields, hides _id.
🟢 5. Query Operators
Comparison operators:
👉 Used for comparisons like greater than, less than, in.
Logical operators:
👉 Combine multiple conditions with AND / OR.
Not equal:
👉 Returns students whose grade is not C.
🟢 6. Update Documents
Update one:
👉 Finds student with name Deepak and updates grade to A+.
Update many:
👉 Updates grade for all students with B → B+.
🟢 7. Delete Documents
Delete one:
👉 Deletes the first document that matches name = Tushar.
Delete many:
👉 Deletes all students whose grade is C.
🟢 8. Sorting & Limiting
Sorting:
👉 Sorts results by age in ascending/descending order.
Limiting results:
👉 Returns only 2 documents.
Skipping documents:
👉 Skips first 2 documents.
🟢 9. Indexes
Create index:
👉 Creates index on name field (improves search performance).
View indexes:
👉 Shows all indexes created.
🟢 10. Aggregation (Powerful Analytics)
👉 Aggregation pipeline:
- $match → filter
- $group → group by grade & count
- $sort → order results
🟢 11. Other Useful Queries
Count documents:
👉 Counts students with grade A.
Distinct values:
👉 Finds unique grade values.
Rename field:
👉 Renames field grade → classGrade.
Add new field to all documents:
👉 Adds new field status to all documents.
Common MongoDB Interview Questions
1. What is MongoDB?
MongoDB is a NoSQL database that stores data in flexible, JSON-like documents called BSON. It's schema-less and great for handling large, unstructured data.
2. What are the advantages of MongoDB?
Flexible schema, easy to scale, fast for large datasets, supports geospatial queries, and works well with modern apps like web or mobile.
3. What is a document in MongoDB?
A document is a single record in a collection, stored as a JSON-like object with key-value pairs.
4. How does MongoDB ensure high availability?
Through replication, where data is copied to multiple servers (replica sets). If one server fails, another takes over.
5. What is sharding?
Sharding splits large datasets across multiple servers to improve performance and handle big data.
6. How do you handle relationships in MongoDB?
- Embedding: Storing related data in a single document
- Referencing: Storing related data in separate collections and linking them with IDs
7. What is an aggregation pipeline?
It's a series of stages (like $match, $group, $sort) to process and transform data, similar to SQL's GROUP BY or JOIN.
8. When would you not use MongoDB?
For highly relational data, complex joins, or applications needing strict ACID transactions (e.g., banking systems).
Tips for Interview Preparation
- Understand CRUD: Be comfortable with Create (insert), Read (find), Update (update), and Delete (delete) operations.
- Practice Queries: Run MongoDB queries on a local database (use MongoDB Compass or the MongoDB shell).
- Know Indexing: Explain how indexes improve performance and their trade-offs (e.g., slower writes).
- Explain Scalability: Talk about sharding and replication confidently.
- Compare with SQL: Be ready to discuss when to use MongoDB vs SQL based on use cases.
Sample MongoDB Query Scenario
Question:
You have a products collection with documents like:
Write queries to:
- Find all products in the "Electronics" category.
- Update the price of the "Laptop" to 1200.
- Count products with a price greater than 100.