📚 Database Indexing - Complete Interview Notes
1. What is Database Indexing?
Definition: Indexing is used to quickly retrieve particular data from the database. It is a
technique that uses data structures to optimize the searching time of a database query in DBMS. Indexing
reduces the number of disks required to access particular data by internally creating an index table.
Index Structure
Index Table Structure

Search Key: Contains copy of Primary Key or Candidate Key (stored in sorted manner)
Data Reference: Set of pointers holding address of disk block containing actual data
3. Types of Indexes
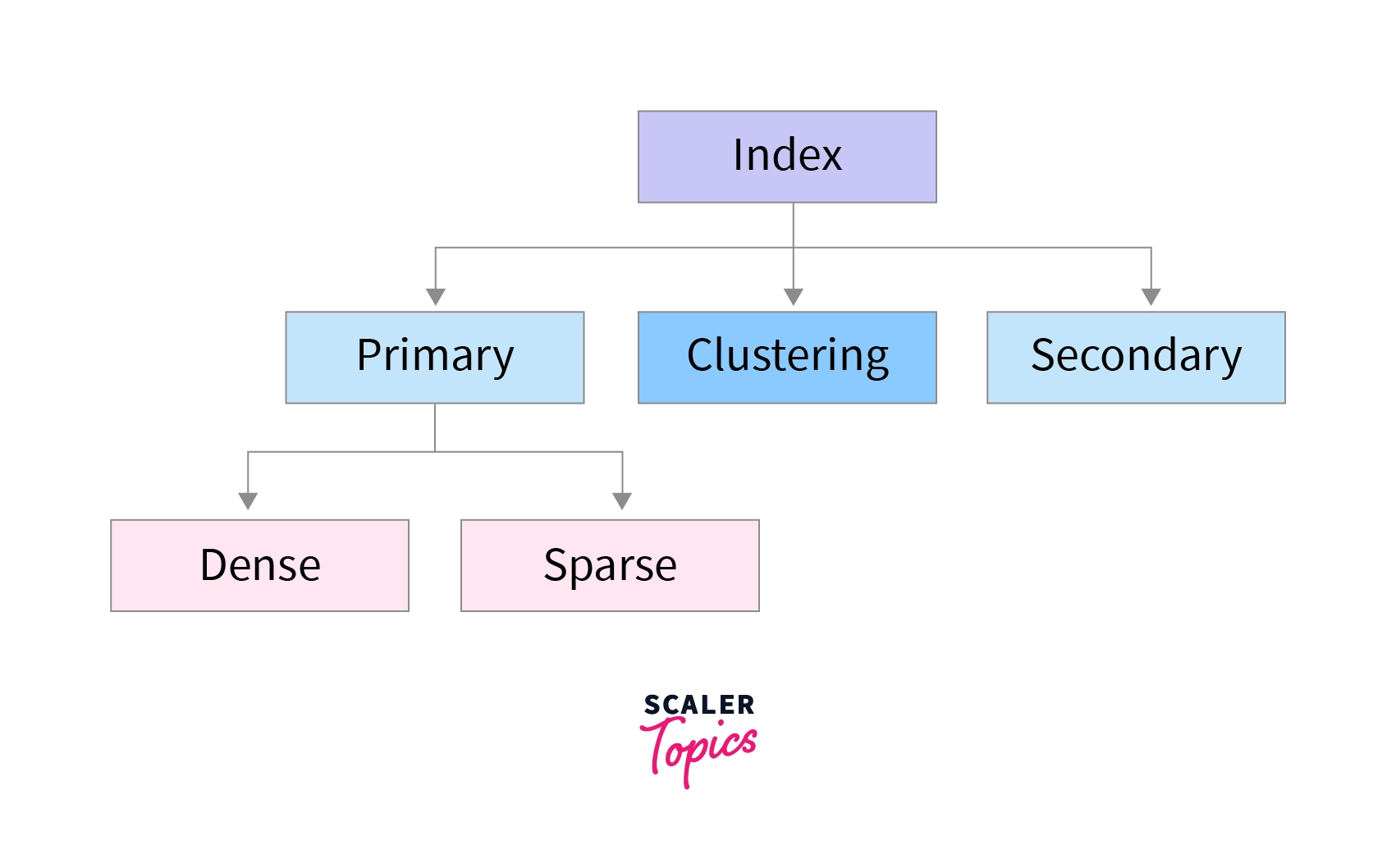
Single Level Indexing
Single Level Indexing is like index found in a book. Contains topic names along with page numbers.
Similarly, database index contains keys and their corresponding block addresses.
A) Primary Indexing (primary key and Ordered data)
Definition: Index table created using Primary keys. Defined on ordered data.
Example: If student table is sorted by student_id (primary key), then primary index will contain student_id and corresponding block addresses.
Example: If student table is sorted by student_id (primary key), then primary index will contain student_id and corresponding block addresses.

Characteristics of Primary Indexing:
- Search Keys are unique
- Search Keys are in sorted order
- Search Keys cannot be null
- Fast and Efficient Searching
- One-to-one relationship with data blocks
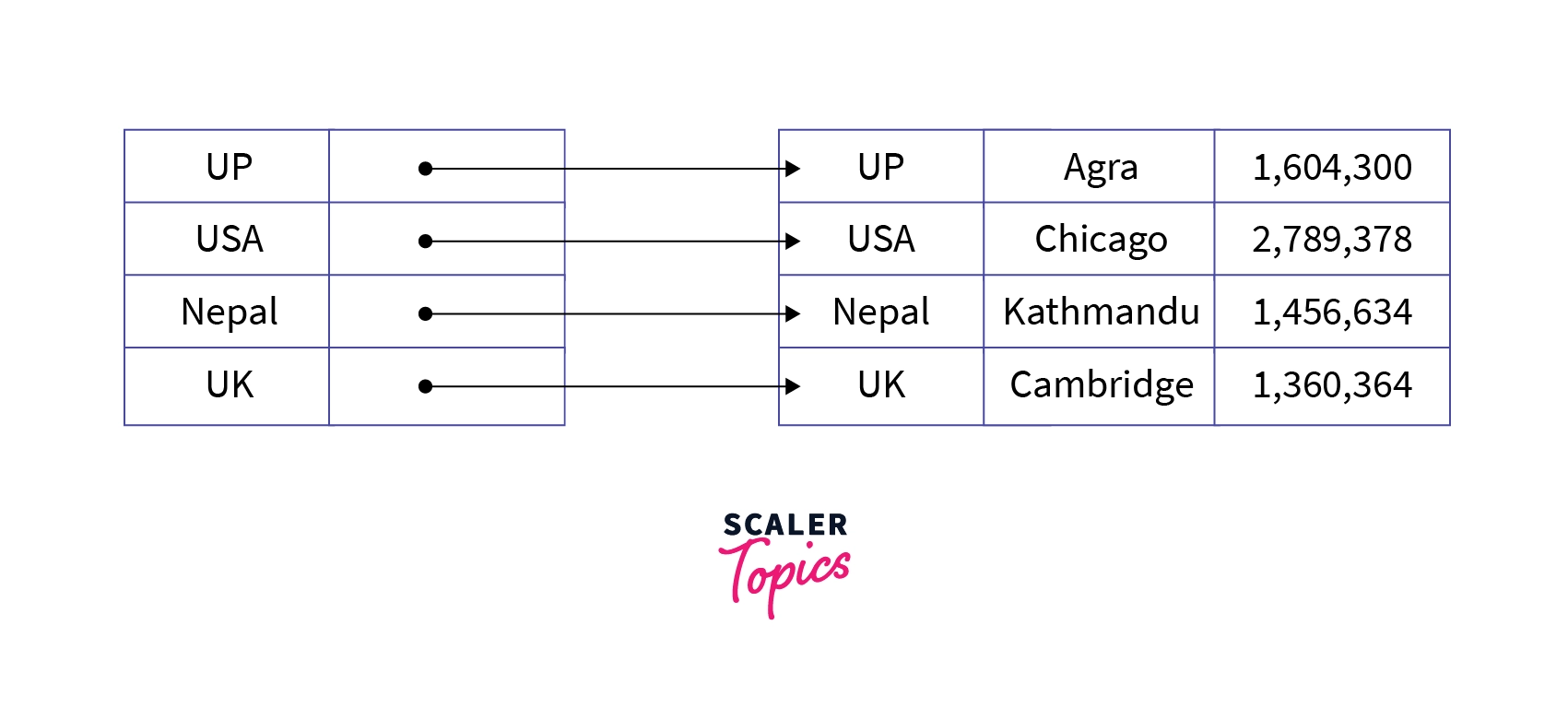
B) Secondary Indexing
Definition:
Secondary Indexing is an additional index created on non-primary attributes (other than the primary key).
It allows faster searching on columns like Name or City, even if they are not sorted.
It is also known as Non-Clustered Indexing.
- Primary index → built only on the primary key (unique, one per table).
- Secondary index → built on other columns (can be unique or non-unique).
- Helps in searching efficiently without scanning the whole table.
Secondary Index Structure
Characteristics of Secondary Indexing:
- Can be created on any column (not just the primary key).
- Search Keys may be unique (e.g., Email) or non-unique (e.g., City).
- Index entries are sorted, but the actual data is not necessarily sorted.
- Multiple secondary indexes can exist in one table.
- Requires extra storage and update overhead.
- Faster than a full table scan but slower than primary indexing.
C) Cluster Indexing (ordered but non key)
Definition: Used when multiple related records are found at one place. Defined on ordered
data. Index created using non-key values which may or may not be unique. Groups columns having similar
characteristics.
Cluster Index Structure
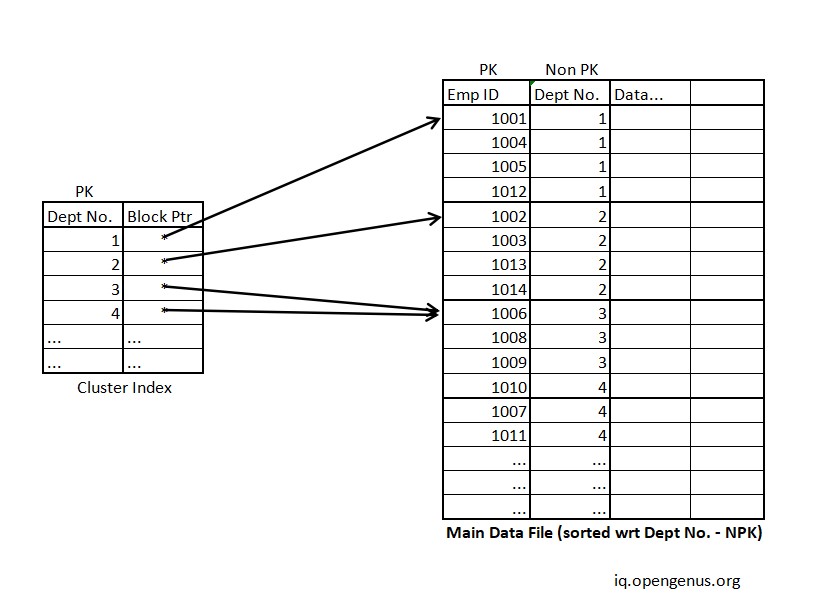
Characteristics of Clustered Indexing:
- Search Keys are non-key values
- Search Keys are sorted
- Search Keys cannot be null
- Search Keys may or may not be unique
- Requires extra work to create indexing
- Good for grouping similar records
Ordered Indexing
Ordered indexing is traditional way of storing that gives fast retrieval. Indices are stored in sorted
manner, hence also known as ordered indices.
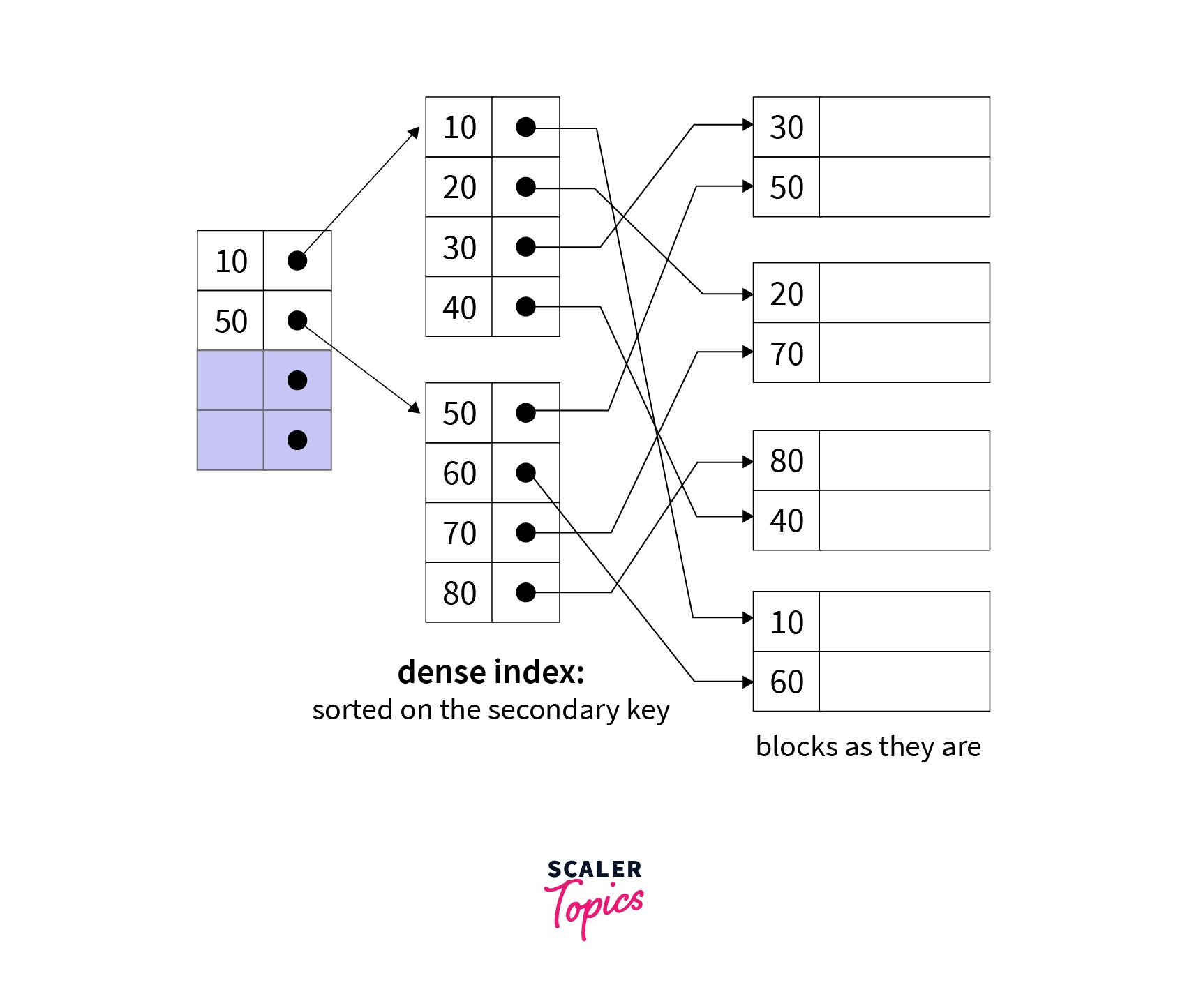
A) Dense Indexing
Definition: Index table contains records for every search key value of the database. Makes
searching faster but requires more space.
Dense Index Example
Every search key has corresponding index entry
B) Sparse Indexing
Definition: Consumes lesser space than dense indexing but is slower. Does not include
search key for every record. Store search key that points to a block containing group of data.
Sparse Index Example
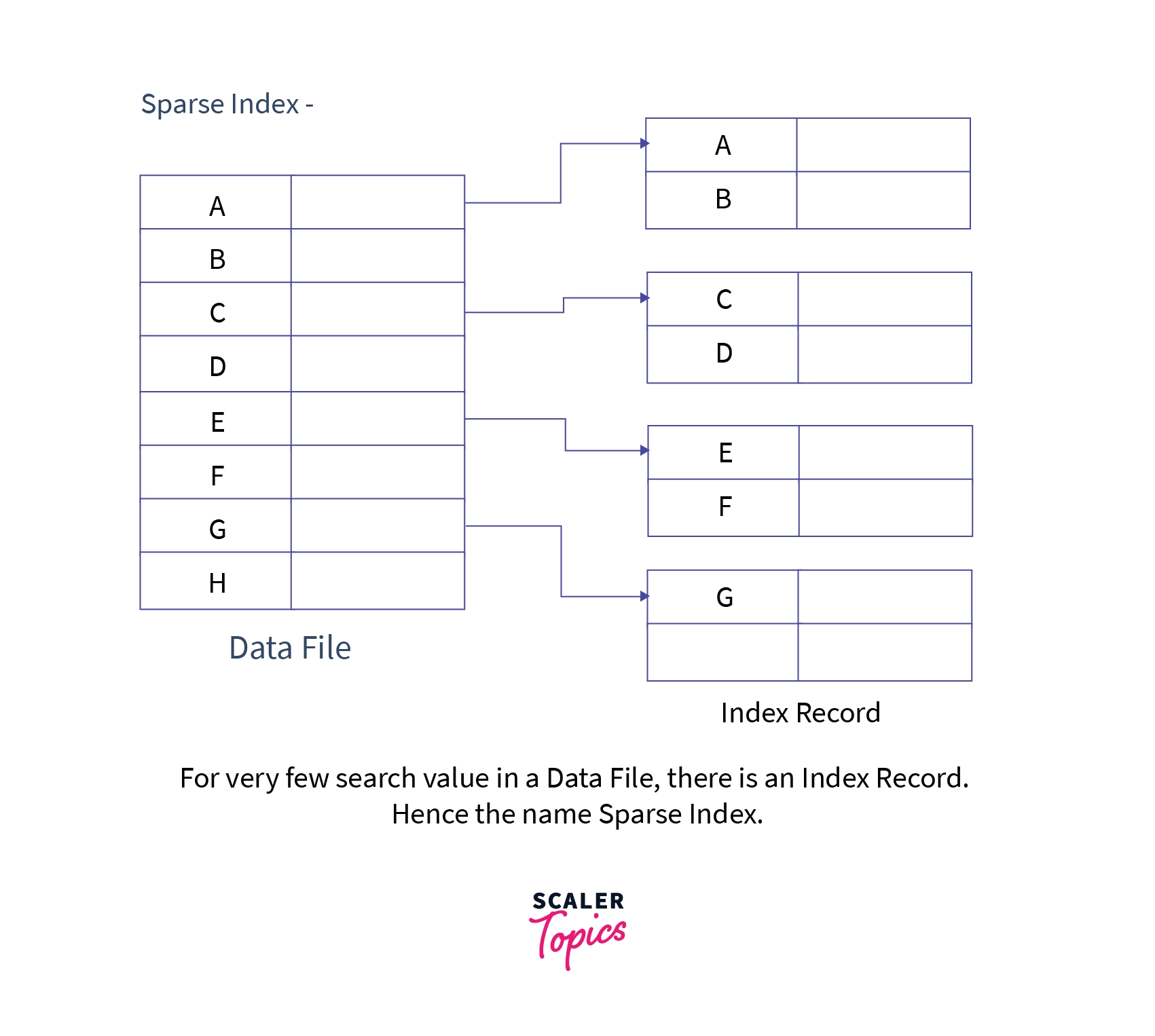
Selected search keys point to blocks containing multiple records
Key Difference: Dense indexing has entry for every record, Sparse indexing has entry for
selected records only.
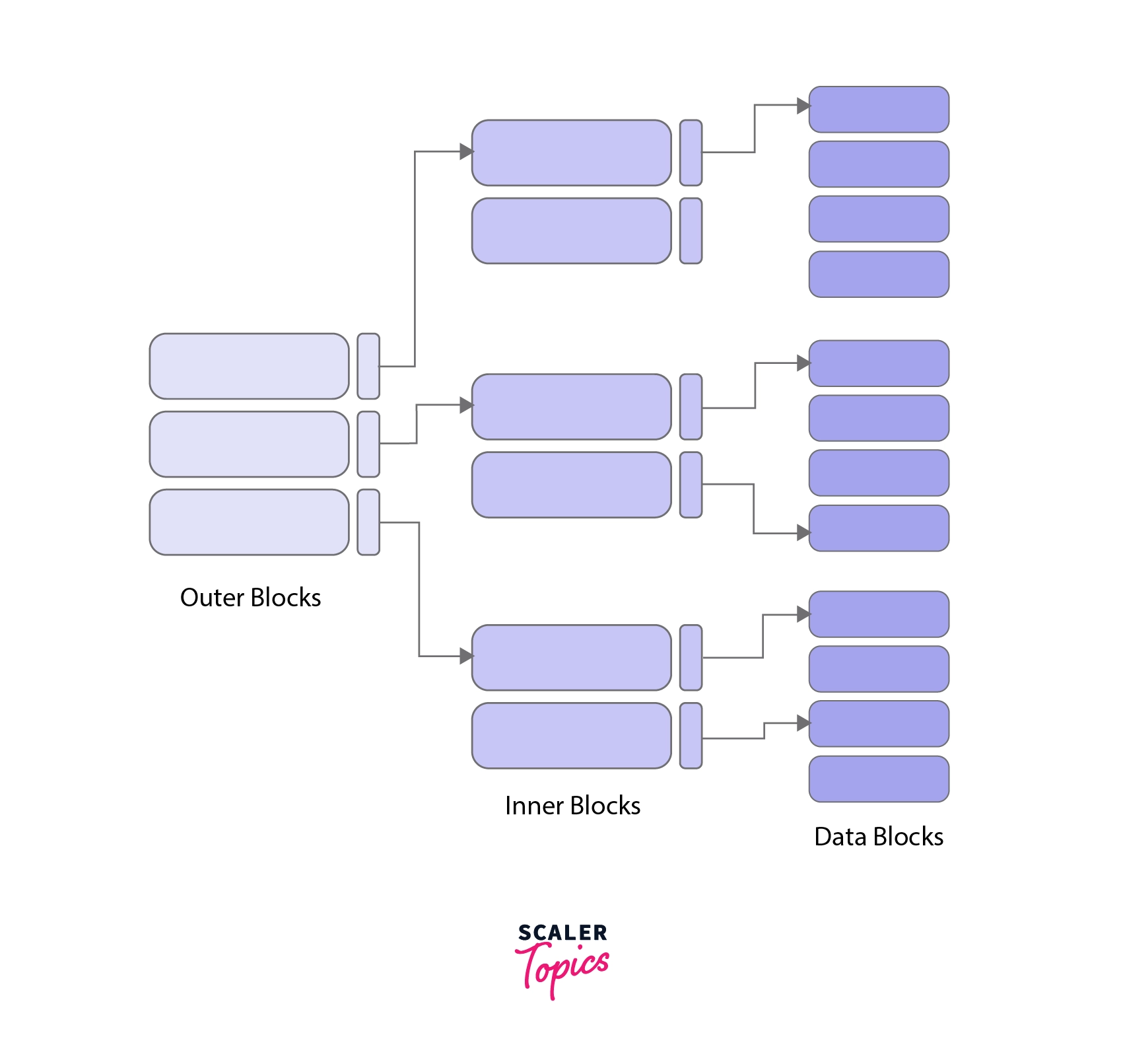
4. Multi-Level Indexing
When a database is very large, the index table itself becomes large. Storing such a big index in memory
takes a lot of space.
Multi-Level Indexing solves this problem by creating a hierarchy of indexes:
Multi-Level Indexing solves this problem by creating a hierarchy of indexes:
- It breaks the large index into smaller index blocks.
- One small index points to another index, and that index finally points to the data.
- The top-level index is small and easy to keep in memory.
Multi-Level Index Structure
B+ Tree for Multi-Level Indexing:
- Leaf nodes contain the actual data or data pointers.
- Leaf nodes are connected using a linked list.
- This helps in fast range queries (example: find data from 10 to 100).
- Non-leaf nodes only contain keys for search navigation.
5. B-Tree vs B+ Tree (Simple and Clear Explanation)
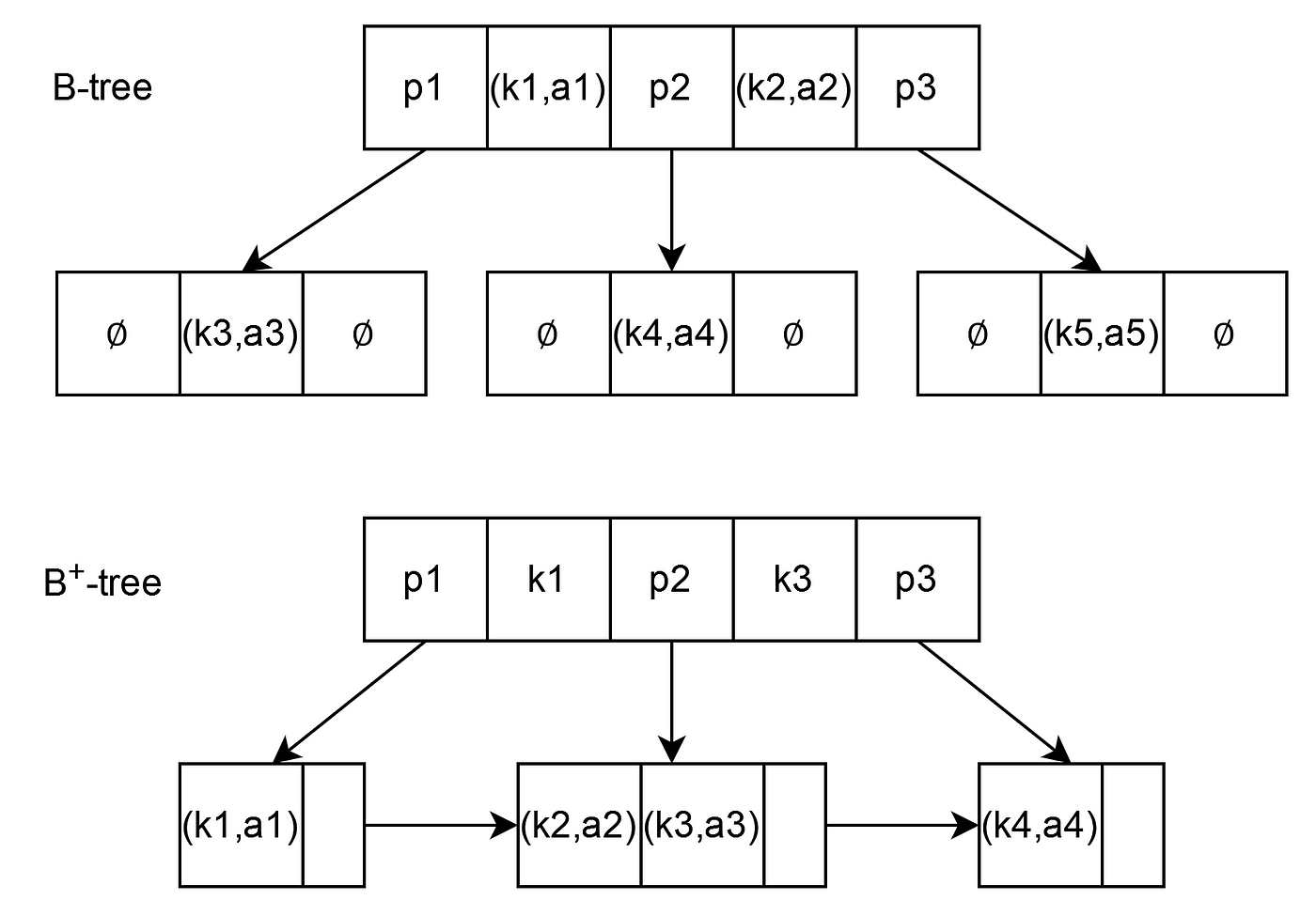
What is a B-Tree?
B-Tree is a tree-like structure used to store and search data efficiently.
How it works:
How it works:
- Each node can store keys and data.
- It keeps data sorted and balanced.
- Helps in quick search, insert, and delete operations.
What is a B+ Tree?
B+ Tree is an improved version of B-Tree, used in most databases.
How it works:
How it works:
- Only leaf nodes store the actual data.
- All leaf nodes are connected using a linked list.
- Internal (non-leaf) nodes only help in searching.
- Fast range and sequential access (because of linked list).
- Consistent search time (all data at same level).
B-Tree vs B+ Tree Comparison
| Feature | B-Tree | B+ Tree |
|---|---|---|
| Data Storage | All nodes (internal + leaf) store data | Only leaf nodes store data |
| Leaf Node Connection | No connection | Connected by linked list |
| Range Queries | Slower and complex | Faster and simple |
| Sequential Access | Difficult | Easy (just follow the linked list) |
| Memory Usage | Less | More (some keys are repeated) |
| Used In | File systems | Databases |
Why B+ Tree is preferred in Databases:
- All data is at the bottom level → easy and consistent access time
- Linked leaf nodes → better for range and sequential queries
- Higher fan-out (more children per node) → fewer levels in the tree
- Efficient for large databases where fast searching and scanning is needed
6. Advantages of Indexing
- Faster Query Results: Quick data retrieval instead of full table scan
- Faster Sorting and Grouping: Index keys already sorted
- Efficient Searches: Sorted and unique keys retrieve queries faster
- Less Memory Usage: Index tables smaller than main tables
- Main Memory Storage: Index stored in main memory for speed
- Bridge Speed Gap: Reduces difference between CPU and secondary memory speed
- Better Performance: Improved CPU utilization and overall system performance
7. Summary Points for Interview
Key Takeaways:
- Indexing uses data structures to optimize database query searching time
- Index table has Search Key (sorted) and Data Reference (pointer)
- Three main types: Single-level, Ordered, and Multi-level indexing
- Single-level: Primary (fastest), Secondary (flexible), Clustered (grouped)
- Ordered: Dense (every key) vs Sparse (selected keys)
- Multi-level uses B+ Trees for large datasets
- B+ Tree preferred over B-Tree for databases due to linked leaf nodes
- Main benefit: Faster data retrieval and better performance
Remember: Most commonly used indexing attributes are B-trees, Bitmap, Ascending/Descending,
Column/Functional, Single/Concatenated, and Partitioned/Non-partitioned.